


Welcome to this guide on deploying Llama2 LLM (Large Language Model) on Google Cloud Platform (GCP). In this guide, we’ll take you through the process of setting up and utilizing Llama2 LLM on GCP, ensuring you have the knowledge and tools to fully leverage Llama 2’s capabilities. If want to read more about Llama 2 please refer to the blog where where we explain a comparison of different Llama 2 models along with the hosting rate per hour for AWS, GCP and Azure.
So, what can you do with Llama2 on Google Cloud?
- Deploy Llama 2 out of box and serve it as an API endpoint to your own end users.
- Fine tune Llama 2 directly on Google Cloud with your own data.
- Improve Llama 2 with Reinforcement Learning with Human Feedback, or RLHF.
- Finally, you can check the safety attributes using content moderation on Google Cloud as well.

Sign up for a Google CloudPlatform
- If you don’t have a Google Cloud Platform account, sign up as a new user and you may be eligible for free credits.
You might be wondering, what size of model should I start using, 7, 13, or 70? Well, if you're just starting out, you might want to consider starting with the 13 billion model. If you find that the quality of the responses is not quite good enough, then you can always change to the 70 billion model. If you find that with the 13 billion model the latency is too slow and the response quality isn't a major concern, then you can go down from the 13 billion to the 7 billion.
How to get started
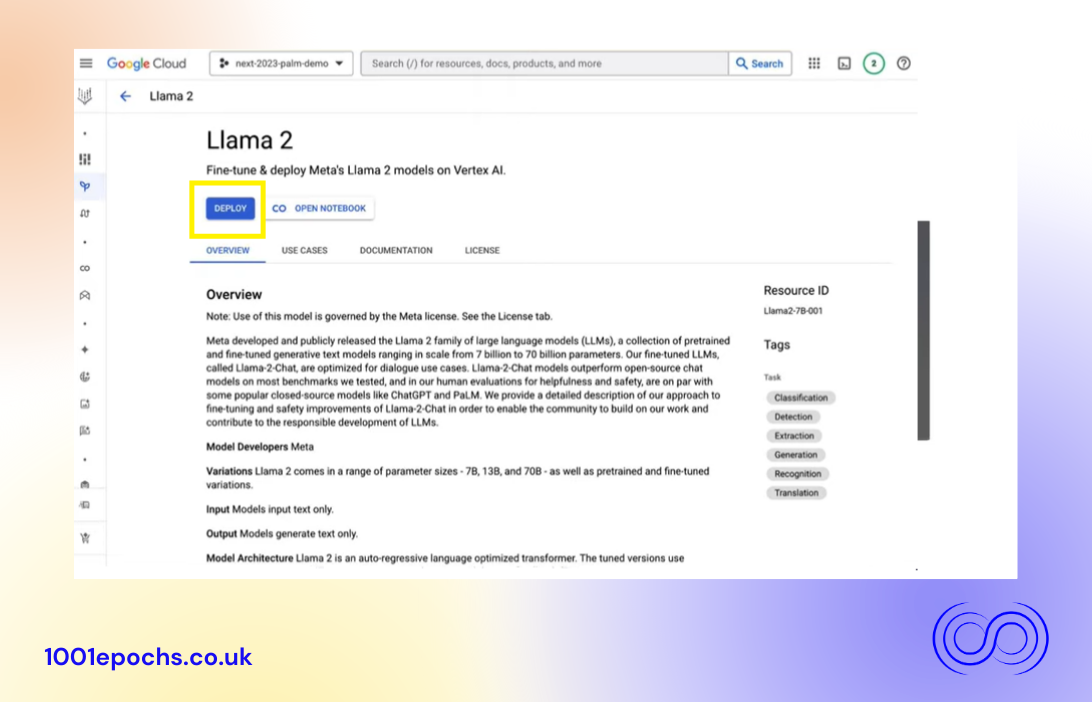
Once your account is set up on Google Cloud, navigate to Vertex AI Model Garden and look for the Llama2 card. Click on the card to view details. As you can see in the figure on the model card, there is a Click to Deploy button, which allows you to save Llama 2 to Vertex AI Model Registry and deploy it to an endpoint that. From a Llama 2 Model Card on Vertex AI Model Garden, you can either deploy the model in the Console using the Deploy button here or deploy the model through code using the notebook. Let's start with deploying from the Console by clicking on Deploy.
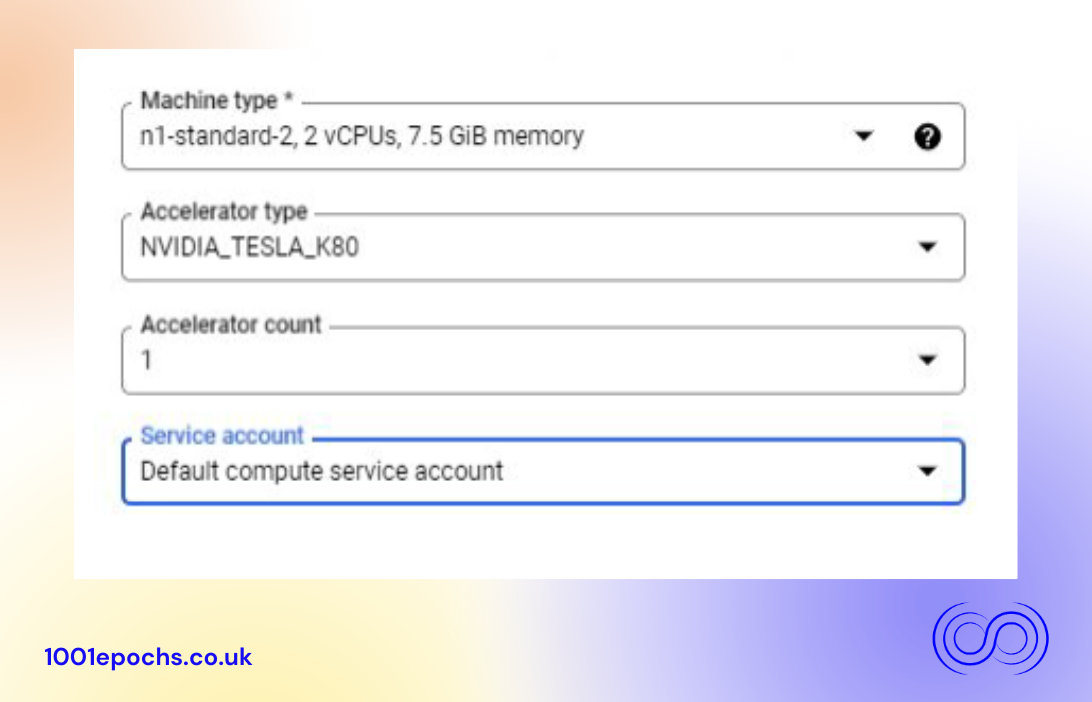
After that you'll need to choose which Llama 2 variation you want. Save it as a new model, give it a custom name, then click Save to save to Vertex AI Model Registry. Set the access level to Standard and click Continue to get to the model settings. Set the minimum number of compute nodes to 1 for proof-of-concept purposes.

If you plan to run Llama 2 7B,select n1-standard-2 machine, in conjunction with the Nvidia K80in this case, but any equivalent GPU will suffice. (The GPU model availability might differ from region to region. For the 13B and 70B the a2-highgpu-1gwith the appropriate GPU for the respective model will be enough. We refer reader to blog for the cost comparison if not sure about the cost.
Finally, after saving the settings and deploying, you may go to the model registry page. Navigating to Vertex AI Model Registry, you should now see your model, but note that it hasn't been deployed to an endpoint yet. To deploy the model, you can click on the three dots on the right-hand side, and then click on Deploy to endpoint as shown in the figure and follow the instructions within to deploy with GPU accelerators.

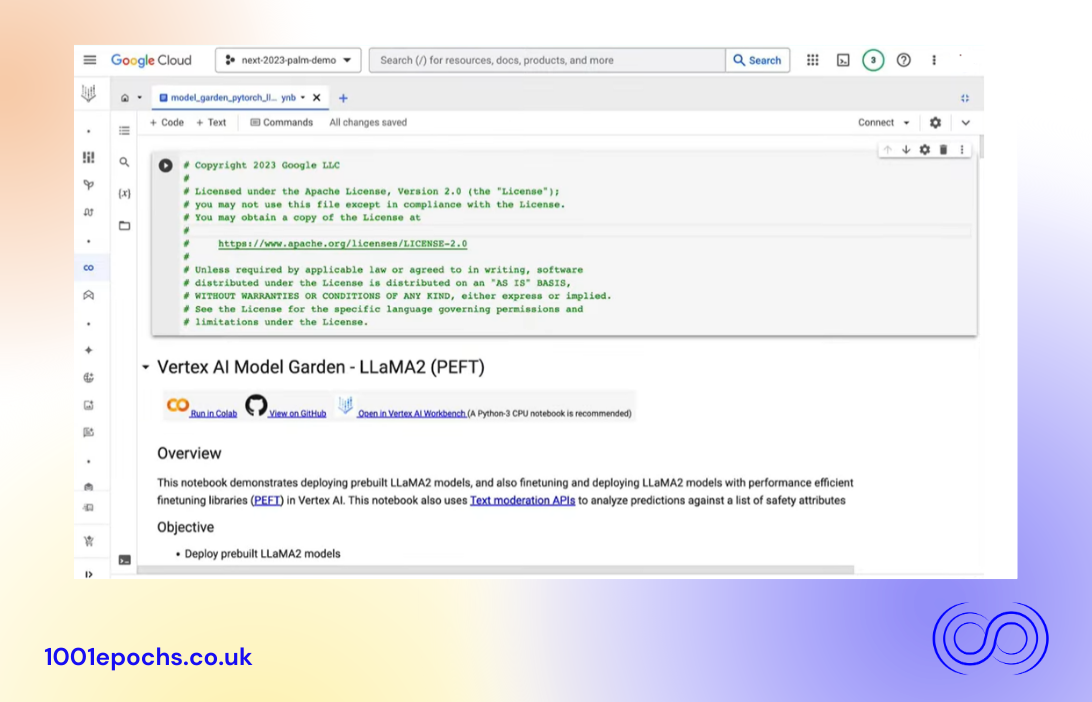
Now, if you'd prefer to work in a coding environment, instead of the UI, you can also walk through the deployment of Llama 2 in the Colab Notebook, which you can find by clicking on Open Notebook from the Llama 2 Model Card on Vertex AI Model Garden. The notebook is also where you will find the instructions on how to perform adapter tuning with Llama 2, instructions for RLHF, and also, content moderation to check for safety attributes in the model responses.
Check model functionality testing the deployed Llama2 model by sending a JSON request to the model. Compose a JSON request according to your specific requirements submit a JSON request by clicking Predict and the model will process your input text and provide a response.
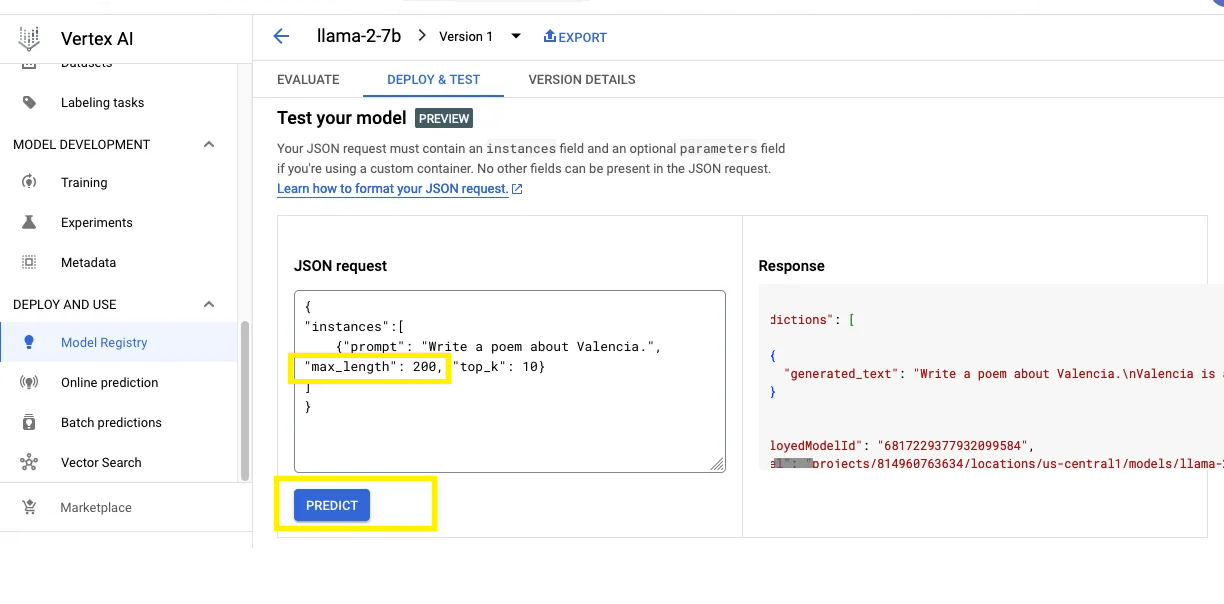
Deploying Llama 2 on Google Cloud's Vertex AI offers a flexible environment for serving the model via API, fine-tuning with custom data, and enhancing its capabilities with RLHF. Through a straightforward UI or a Colab Notebook, users can effortlessly integrate Llama 2 into their applications, unlocking the potential of advanced language processing on the GCP infrastructure.

.png)

.png)
